Like ARM, Ceva is purely an intellectual property (IP) firm which does not sell silicon. Its main products are baseband PHY DSPs – it claims to have IP in every third mobile phone – six billion DSPs.
As it announced the processor, Ceva revealed details of the architecture behind it, which is going to be used in a series of processors.
Mobile World Congress: Your Electronics Weekly guide »
The biggest change from its current architecture is that the new one allows the DSP cores to behave far more like a conventional CPUs when executing control rather than number-crunching tasks.
Some nomenclature
The firm’s existing architecture is called Ceva-X, the new architecture is called New Ceva-X, and the new core is called Ceva-X4 (rather than New Ceva-X4). Ceva-X4 is intended for the highest tier of smart phones which will be able to download 1Gbit/s data during a voice conversation.
“New Ceva-X delivers 2x more DSP horsepower while consuming 50% less power than the previous generation Ceva-X,” said the firm.
Ceva-X4 and is a quad-core 128bit wide VLIW and SIMD processor with a 10-stage pipeline. The cores are identical and are dubbed ‘scalar processing units’ (SPUs). Later New Ceva-X products will have fewer SPUs and be aimed at less complex processing.
Compared with Ceva’s earlier X1643, in control tasks X4 doubles processing capability to score 4.0 CoreMark/MHz.
The firm refers to X4 as a ‘baseband control processor’ rather than simply a ‘baseband processor’ because, while it will handle the entire transmit and receive chains in lesser applications, it requires a powerful partner DSP (XC4500 with 64 MAC vector engines, see diagram) to handle the intense processing load of a 4G receive chain with both five-way carrier aggregation and multi-RAT (radio access technology).
 Carrier aggregation involves using up to five 20MHz-wide bands to provide 100MHz bandwidth through which to deliver 1Gbit/s downloads to a phone. “Baseband and PHY complexity scales with the number of carriers. Today, super-high-end phones only have three 20MHz bands,” Ceva business development director Emmanuel Gresset told Electronics Weekly.
Carrier aggregation involves using up to five 20MHz-wide bands to provide 100MHz bandwidth through which to deliver 1Gbit/s downloads to a phone. “Baseband and PHY complexity scales with the number of carriers. Today, super-high-end phones only have three 20MHz bands,” Ceva business development director Emmanuel Gresset told Electronics Weekly.
Multi-RAT is simultaneous 4G and 3G or 2G so that voice (2 or 3G) and data (4G) are available at the same time.
Controlling baseband hardware is where the need to microcontroller as well as DSP capability springs from. Ceva points out that, for example, implementing a Voice-over LTE (EVS) codec is largely a DSP activity, while LTE PHY control needs a lot of controller-type processing, and WCDMA PHY control is even more controller code biased.
On the DSP side, each of the four SPUs has a MAC that can be configured as a single 32×32 MAC or two 16×16 MACs. Then there are optional IEEE single-precision floating point units – up to four per X4. “Floating point is used for matrix operations – in LTE you have to invert a matrix – and some audio processing needs floating point”, said Gresset.
The architecture is seven-way VLIW. “That is seven 16 or 32bit instructions: one instruction per SPU, one load instruction, one store instruction and one programme control instruction,” said Gresset. “If a future processor has one SPU, it will be four-way VLIW.”
SIMD is 128bit: 4x32bits or 8x16bit, and the memory bus can be 256bits wide.
11 instructions per cycle can be executed – 8xSIMD plus three others, which means the 16Gop/s figure can be achieved at 1.5GHz – a speed which Ceva predicts from a 16nm finfet process.
There are now special instructions for FFT and Viterbi – add-compare-select is a single one cycle instruction, when it previously took 5-10 cycles, and there is native support for post-shift and saturation.
According to Gresset, there was a nod to microcontroller-like behaviour in the previous Ceva-X architecture, but it was not optimised and the focus was largely DSP-only. With New Ceva-X, a lot of work has been done on the SPUs to improve the way they execute control code.
For example, apart from branches, instructions are now single cycle – including the 32bit multiply and divide.
 Byte operations have been included. “DSPs are typically 16 or 32bit and not very good for 8bit operations. For control code, you do a lot of 8bit manipulation, and we didn’t have that at all. So we have added it and you can load 8bits at a time and do bit manipulation,” said Gresset.
Byte operations have been included. “DSPs are typically 16 or 32bit and not very good for 8bit operations. For control code, you do a lot of 8bit manipulation, and we didn’t have that at all. So we have added it and you can load 8bits at a time and do bit manipulation,” said Gresset.
Some 64bit support is also included – add and subtract in one cycle, but not single-cycle multiply.
To go along with the ability to load one byte, non-aligned support has been added to memory, including instruction and data caches. The memory subsystem supports non-blocking two-way or four-way caches with hardware and software pre-fetch capabilities.
To help the associated C compiler, there is an increased number of registers, and they can be used for anything – a generic orthogonal register set.
“The compiler is integral part of core,” said Gresset, pointing out that gone are the days a DSP could be optimised separately from its compiler. “Control code and DSP code is written in C so you need to optimise the compiler and core at the same time.”
Branch-prediction has been enhanced with hardware that runs statistics for dynamic prediction. “Typically DSP only needs static branch prediction and typically a controller needs dynamic branch prediction,” said Gresset, adding this includes an “advanced” branch target buffer.
The instruction pipeline in the x4 has 10 stages, although the Ceva-X architecture allows five-stage pipelines to be integrated for simpler applications. A shorter pipeline could actually improve the CoreMark score slightly, added Gresset. “and it might not, it is too early to tell.”
As an aside, bringing in multiple parallel cores is not a good way to improve CoreMark scores, he said because the benchmark code is largely non-DSP control code which you are “hardly able to parallel, it will be very similar if there is one or four processors”.
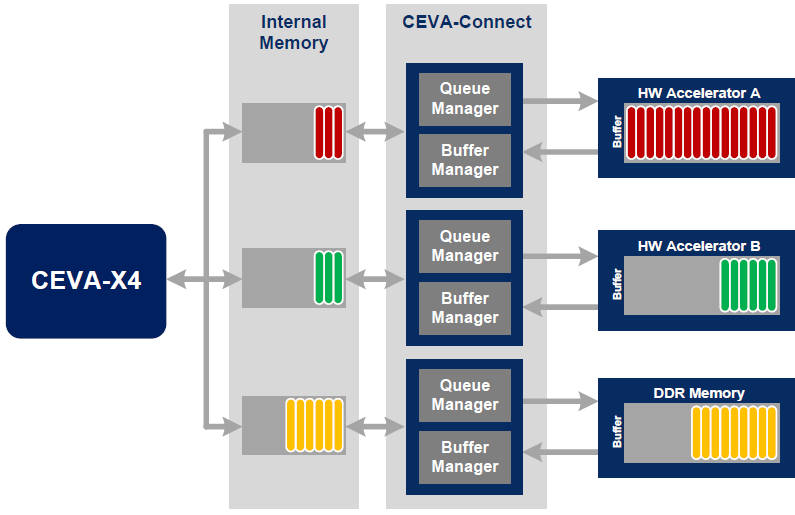 New hardware, branded Ceva-Connect, orchestrates the movement of data between hardware accelerators, co-processors, SPUs and DDR memory – something that was not included in the original architecture at all.
New hardware, branded Ceva-Connect, orchestrates the movement of data between hardware accelerators, co-processors, SPUs and DDR memory – something that was not included in the original architecture at all.
Based on ‘q-man b-man’ (queue manager and buffer manager), and pioneered in the powerful XC4500 DSP, it maintains multiple independent tasks queues and has flexible priority and tasks queues for improved quality of service (QoS), said Ceva. It also has dedicated ports to the various accelerators.
Data is automatically partitioned and fetched without SPU intervention to the point “it will handle a movie download for minutes,” said Gresset.
As well as off-loading the SPUs, the manager smooths out bus traffic by reducing peaks caused by SPUs responding to interrupts requesting data transfers. In some cases, this can allow a narrower on-die bus to be used.
What there isn’t
Ceva is aiming the X4 solely at baseband processing, so while a lot of hardware functions have been added, some have not.
“There is no super-scalar and no out-of-order execution,” said Gresset. “Those are not needed for baseband processors. They are only needed in high-end control processor when they need to do things like run Linux. Instead, we have fast context switching for multi-tasking.”
In operation, tasks like power measurement on 20MHz carrier bands are not directly mapped to individual SPUs.
“You don’t need to. Four SPUs is what we need to handle five carriers – not only five carriers, but 3G or 2G as well,” said Gresset. “The RTOS will split into tasks and hand one off after the other, so all four SPUs do measurement on carrier one, then all four SPUs work on carrier two, and so on.”
According to him, there is enough capacity to handle ‘dual connection’ from LTE-Advanced Pro Release 13 – one handset connecting to two basestations at the same time – something which doubles processing complexity.
According to Gresset, some phone vendors implement voice compression in the PHY controller to save adding an audio processor core, and the X4 has enough capacity to run the new EVS voice codec alongside everything else – something which takes 10x more memory and five times more computing than the wideband AMR codec. By the way, he commends EVS: “Voice is very high quality and it does voice and audio equally well.”
If your super-phone is going to need a XC4500 anyway, why not do everything in that and forget the X4?
Gresset’s answer is that it would be power inefficient, adding that in a basestation an XC4500 could indeed control multiple XC4500s.
Away from phones, said Gresset, future New Ceva-X processors with only one or two SPUs will be developed to handle a spectrum of baseband applications from the X4 down to simple machine-to-machine modems.
What else at MWC?
As well as showcasing the X4 high-end mobile phone baseband processor at Mobile World Congress this week, Ceva is demonstrating Dragonfly 2, a machine-to-machine platform that implements LTE Cat-0 using the firm’s XC5 processor and an FPGA.
Actually, said Ceva, it “supports every M2M standard including: LTE MTC Cat-1, LTE MTC Cat-0, LTE MTC Cat-M, 802.11n/ah Wi-Fi, PLC, 802.15.4g, ZigBee, GNSS, LTE-OTDOA, NB-IoT, LoRa and Sigfox”.
At MWC, Dragonfly will be operating dual-mode inside a flying drone – implementing LTE Cat-0 comms and a GPS receiver.